
Automatic Tests as Catalyst for Software Development
The potential
In chemistry, a catalyst is defined as a substance which does not partipate in a chemical reaction but increases its rate.
Automatic tests can be the super-catalyst for the software projects. That is, they do not produce any value by itself but well-made suites of automatic tests can do wonders to software projects, no matter whether big or small.
Well-written tests are a relatively rare sight and therefore often undervalued, as well as surrounded by myths and misconceptions. In other words, while tests can be a catalyst, they often do not reach the critical quality mass to become one. In this article, I shall attempt to illustrate why – in broad terms.
Myths
Good automatic tests can be written by part-time junior-level employees
In reality, good automatic tests require time, skills and a particular mindset. Some test-related skills are wider than respective development-related skills.
Writing tests is a mindless work since they just duplicate the code
Good automatic tests are written on a different abstraction level than the code they test. Choosing good test interfaces is crucial for the overall quality of the test suite. Balancing between numerous (and often conflicting) properties of test cases is all but mindless work.
Popular commercial and open-source tools provide everything you may need
In reality, while most frameworks do provide entry-level tools to start writing simple test cases, their more advanced tools are sometimes lacking or non-existing. Moreover, in some cases they recommend practices that are actively harmful for the quality of resulting tests (see this section for an example).
Tests are a necessary evil
Bad tests might be. Good tests bring joy and satisfation.
The nature of test mistakes
Examples in this section refer to some test qualities – see the charts below for the full list.
Subtlety
Some of possible mistakes made while writing tests are subtle enough that they stay unnoticed.
Example (test quality interfaces/which-to-test/harness/inputs-ja-outputs): no tests written until late in the development cycle. Consequence: little or no software interfaces which are fit for testing. The cost of writing tests becomes prohibitive. This mistake is commonly referred as “low testability”.
Example (test quality content/cross-coverage): test cases covering various branches of some scenario use same inputs for all branches. Consequence: worse coverage for same amount of time spent.
Example (test quality service/partial-runs): too clumsy or impossible to cherry-pick the set of test cases when developing a particular feature. Consequence: developers not using automatic tests while developing locally.
Non-binariness
Almost all test mistakes are non-binary. In classical software, the outcome of each particular run is either correct or incorrect. In tests, qualities go up and down without somebody able to clearly say “this is wrong” or “this is right”.
Example (test quality: content/granularity): tests are never completely granular or completely ungranural. One might argue, still, that tests are not granular enough (as it’s often the case).
Example (test qualities: interfaces/which-to-test, content/run-cost): the test suite takes 20 hours to execute. Unless this test suite contains tens of thousands of independent test cases, most likely a mistake but it’s impossible to draw a clear line.
Harmful practices
Some sources recommend practices that make writing tests deceptively easy. Must be a good thing, right? Too bad, such practices often result in bad tests.
Example (test qualities: content/readability, content/maint-cost): auto-generating test code, also known as test recording. Consequence: tests are hard/impossible to read, test hooks are impossible to make, small changes in UI/API require a re-recording of every test case.
Claims
Having participated in numerous software projects, I’d claim that:
- Good automatic tests improve both the software quality and the development speed.
- Good automatic tests serve as “living documentation” – that is, always up-to-date
technical specifications. - Good automatic tests are significantly harder to write than good executable code.
- Good automatic tests require significant initial investment as well as continuous
maintenance. - Many software projects have severely underperforming suites of automatic tests.
Illustrations
Like many other things in computer science and software development in particular, measuring long term-effects is notoriously difficult and often borderline impossible. This section contains pictures summarising the subjective experience based on a fictive example project.
While the model and the numbers are made up, I am reasonably convinced that the curve shapes could be applied to illustrate challenges in real past projects I’ve seen or participated in.
Complexities of writing executable code vs. automatic tests
The following two pictures illustrate the complexity of writing automatic tests as opposed to writing code/configuration. Each of these 2 tasks is split into a number of qualities associated with an output of the task, and each task is viewed as a multi-variable optimisation problem. The exact splits are certainly highly subjective but I have no doubt about the general situation:
- the tests-task have more variables than a code-task;
- deficiencies in test suites are often harder to notice and fix than code deficiencies.
The nature of optimisation problems is that raising a value of any particular variable generates a downward pressure for at least one other variable (and often several of them). In my experience, a handful of test-task variables are either forgotten or not optimised for.

In the surrounding pictures (above and below), solid areas indicate the relative amount of things in a particular direction where a typical project gets it right while the semi-transparent areas indicate the easily achievable potential given a pointed effort. The height of a plot sector indicates how close to the perfection a particular variable value is. The angular width of a plot sector indicates how important (in my opinion) a respective quality is.

The time variable was not included in the model although it’s obviously present for both tasks.
Returns on investments
When tests are made, it’s natural to expect some returns on investments. In best situations, one wants to save more time than invested. Sometimes automatic tests are direct or indirect deliverables and therefore useful even if made “at loss”.
The following three pictures illustrate my perception of three common test development pathways.
Scenario good corresponds to chosen “good” quality values in the previous section.
Scenario typical corresponds to chosen “average” quality values in the previous section.
Scenario bad corresponds to an otherwise average quality values but where a few important qualities
have a very low value.
The 1st and arguably most important picture highlights a huge ROI differences depending on how well the tests were designed. The blue line (“Time spent”) is a reference line which other curves are compared to. Whereever another curve is below the blue one, the ROI is less than 1, i.e. the time spent writing tests is less than the time gained by having less bugs or faster development cycle. Whereever another curve is above the blue one, the ROI is more than 1 – in other words automatic tests did pay off.
In the good-scenario (red line), after a brief period of initial investment, the tests gain traction quickly and give much
more value than spent on them. When that happends, it’s usually easy to convince the project stackholders to continue
the testing effort. If such a situation was prevalent, there wouldn’t be a desire to write this document.
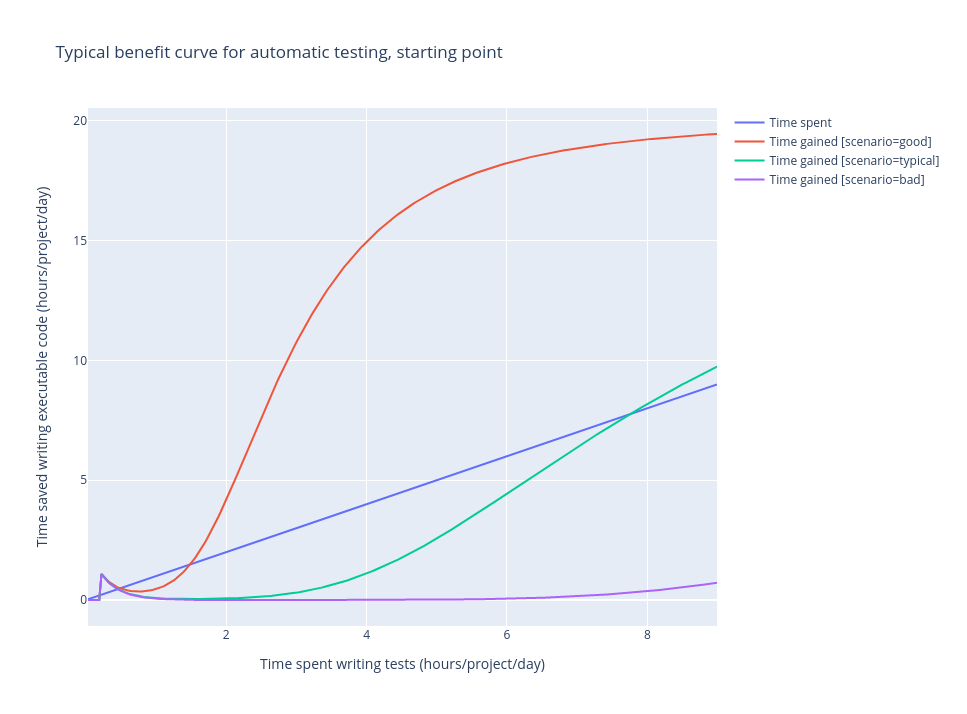
Indeed, what (in my experience) happens more often is the green line. The developers and/or the management know that some
testing is good to have, so a few days are dedicated to “quickly set up the environment and then go back to coding”.
The value of the first few test cases (compared to having nothing) is big enough that it’s almost always a good idea to have
them no matter how the they’re written. It helps that many of the trickier test qualities only begin to show themselves
when the test suites grow. Somebody occasionally manages to make the ‘start, do a dummy thing, finish’-case fail even if
the size of the whole test suite is a grand total of 5 test cases!
Taking into account that there is not yet much to maintain, the pay-off is quite good. This brief period corresponds to the small
sharp bump in the bottom left.
Then things get interesting (or sad, from the point of view of a test writer). Expanding the test suite is suprisingly difficult
as test runs become less stable, take longer time, reports gets messier and the code coverage lags behind. Hours upon hours
are spent with little to show for it. Developers, no longer seeing the value of writing more tests and tired of fixing
existing cases over and over, get increasingly frustrated. Discussions heat up and some hasty conclusions are made, such as:
- “our software is too complicated to be automatically tested”;
- “tests are inherently too expensive to maintain, we can only support N test cases”;
- “tests are too slow and/or annoying to run, it’s faster to test things manually”.
This period is where many do give up. Maybe no more tests are written but at least existing ones mostly work. Or maybe tests quietly
rot away and nobody is paying attention to the e-mails from the CI. After all, if the test suite was red before the change and
is red after the change, what’s the point? Nobody has the time to attend to the whole test suite before solving the next ticket.
Even worse, this period looks very similar between the green line and purple line. In the typical-scenario (green line), there is
at least some pay-off and the test ROI might eventually improve (see the 2nd picture). In the bad-scenario (purple line), the
situation is such that every further hour invested is almost a total loss.

The technical and the social implications are drastically different between the good-scenario and the typical-scenario. Very few
projects, in my experience, get ever close to the red line. Conversely, many projects could reap substantial benefits from
analysing the current state and considering investing more into the test systems. This is true even for projects with a fair
amount of prior test investments.
What is the secret behind high-ROI scenarios, then? In short, well-made test suites empower
developers to make changes without fear of breaking essential things. Tricky bugs, once solved,
do not come back. Developers can iterate code changes locally within minutes, not hours.
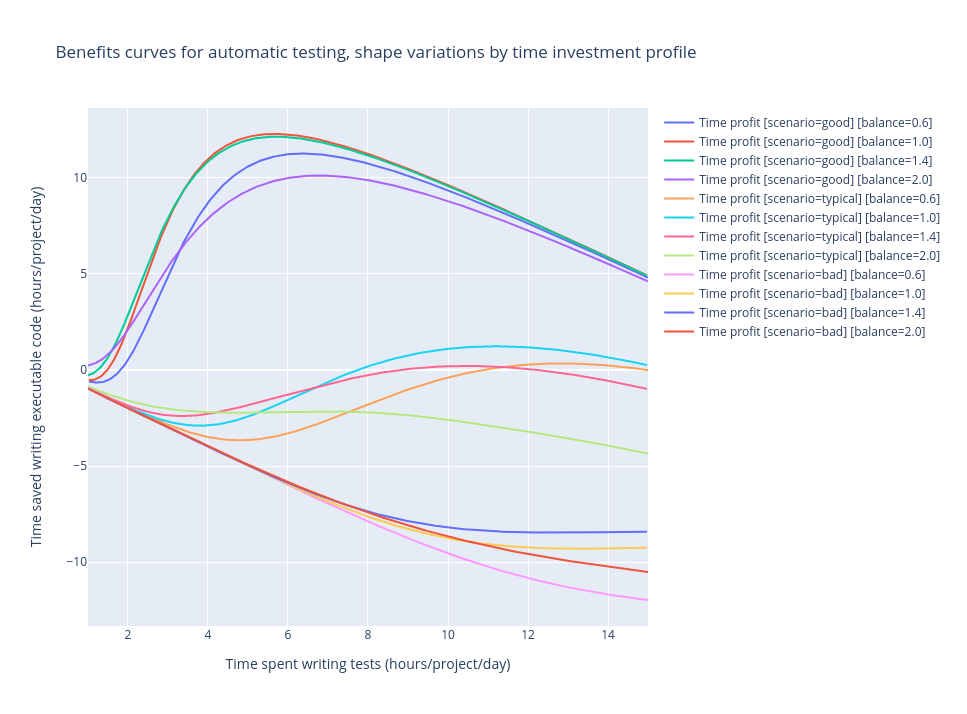
On the 3rd picture, different balance values illustrate how the ROI could change depending on
which test qualities get the most time invested into them. balance=1 simulates that all qualities
get equal time slots, balance>1 simulates that more time is spent on “thicker” qualities,
and balance<1 gives more time to “thinner” qualities. Curiosly, the good-scenario gets positive
outcomes for all balance choices but the typical-scenario has much more uncertainty in this regard.
While, again, this comes from a simplistic model, I find the result plausible in the real life.
Conclusions
Many software projects have untapped opportunities to improve by investing more in automatic testing.
In addition to safe-proofing the software against regressions, good tests can improve the speed of
software development, reduce the amount of re-occurring bugs and make developers happier.